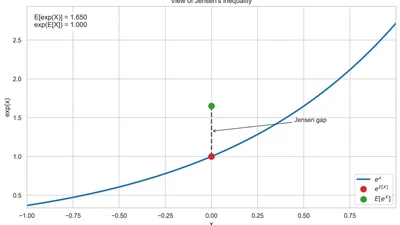
The bias your LLM forgets when you log-transform
Fit a regression on log Y, exponentiate the prediction back, and you've quietly introduced a Jensen-inequality bias. Every codebase I've seen ignores it — and LLMs cheerfully …
Fit a regression on log Y, exponentiate the prediction back, and you've quietly introduced a Jensen-inequality bias. Every codebase I've seen ignores it — and LLMs cheerfully …